
论文Idea
论文Idea
平时写论文的时候有些想法把这些记录下来. 学习Pytorh和深度学习资料.目前找到的比较好的
- ZeroToMastery的pytorch学习资料,有对应的题和答案,质量不错.
- 李宏毅的深度学习课程(建议至少从2021年的看),也有每章对应作业.
- 微软的深度学习以及生成式人工智能课程,高质量,前沿.
- fast.ai的课程Practical Deep Learning for Coders - Practical Deep Learning (fast.ai).内容比较多,关于diffusion models介绍也多.
- 还有Deep Leaning上吴恩达的一些short course,比较实用和前沿(比如Gradio和wandb).
现在生成式人工智能课程内容比较多,llm的内容也比较多,但大多数人没那个训练资源,成本不小.
OPV2V
范围感知CNN,损失函数更改,多尺度attention fusion.
现实世界存在的问题:1)单车目标检测存在的检测问题
2)通信时周围车定位问题
3)通信时带宽问题
三个主要问题通信延迟,数据传输可靠性,定位错误
通过特殊模块(或称为辅助模块)处理通信和点云(特征)互补信息提升可靠性.模块轻量,传递的特征数据少(使用注意力机制).
低延迟和高可靠性是V2V通信面临的两个常见挑战。例如,在碰撞前感知场景中,最大延迟仅为 20 ms,数据传输可靠性必须大于 99%
发射机和接收机之间的障碍物(车辆、建筑物等)会导致信号功率波动,从而造成丢包.
- 通过特殊模块(或称为辅助模块)处理通信和点云(特征),利用互补信息提升可靠性.融合模块轻量,传递的特征数据少(使用注意力机制).
- 强调在真实环境(存在延迟或通信错误情况下)
- 提出特征融合模块?
- 传递的特征根据与ego车辆的距离加权(注意力)?
根据周围车距离进行注意力特征加权,提出去噪模块(optional)作为通信过程中对数据产生的可能噪声的移除.
multiscale range-aware attention
利用较新又好用的attention或者transformer机制进行融合
调研swin-transformer
cnn-transformer?
理想达到的效果,在真实环境(或符合真实环境)下表现优于其他模型(数据集OPV2V,V2V4REAL,V2XSet)
agent置信度?agent confidence?
Range-aware配合单车 localization error减小下提升协同感知能力.
new: Target-aware fuse,设置融合函数更新融合模块权重
点云 需要使用对近处和远处物体有不同探测能力的检测网络 centerpoint raanet
自动驾驶
目标检测 感知
协同感知
motivation
单车occlusion,limited field-of-view
利用车对车技术(或车对infra) 多辆cav同时通信并共享捕获到的传感器信息
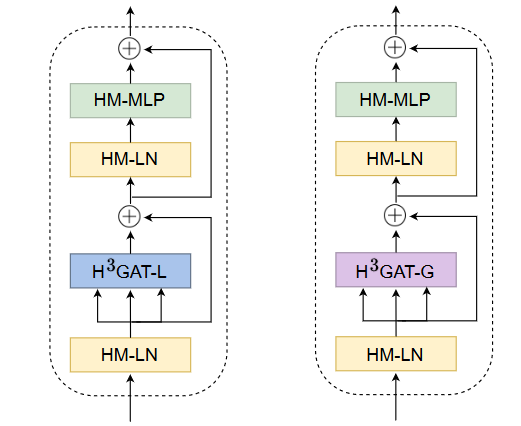
使用多头
2.26
对于多智能体的范围感知的协同融合方法
- 使用了位置编码, 结合局部注意力和全局注意力 促进特征融合,提升协同感知能力.
局部注意力 使用空间信息以及位置信息编码
全局注意力 通道,代理维度上的信息聚集
- 在融合之前使用一个类似去噪增强的模块,方法类似(CoBEVT,CVT等) 尝试使用轻量类似transformer模块提升性能
消融实验
噪声下 wild_setting
三个关键问题 解决pose error(robust to localization error),通信机制,特征融合部分.
局部部分融合coordinate与raan
车之间加一个confidence或者加一个ego的权重
融合车内和车间
通信部分加个损失函数 改进通信图的生成?
结果
我们在理想环境下在三个数据集上进行3D点云目标检测结果进行比较.其中,未进行协作融合作为基线表示只使用一个代理的观察,还包括使用最少数据的晚期融合和使用原始传感器数据的早期融合.为了综合的评价,我们选取了SOTA的方法在多个数据集上实验.在理想环境下,我们的方法超过了早期融合的检测结果,也展现了对之前SOTA方法的优越性.具体来说,AP@50/70在OPV2V的测试集上提升了1.5%/1.5%.相比于其他方法,CoRange利用简单的思想和方法得到了更大的检测性能改进.
Robust to pose error
| loc_err/head_err | AP@0.5 | AP@0.7 |
|---|---|---|
| 0/0(ideal scene) | 0.920 | 0.865 |
| 0.1/0 | 0.916 | 0.848 |
| 0.2/0 | 0.913 | 0.804 |
| 0.3/0 | 0.9 | 0.704 |
| 0.4/0 | 0.89 | 055 |
| 0.5/0 | 0.86 | 0.416 |
| 0/0.1 | 0.919 | 0.860 |
| 0/0.2 | 0.92 | 0.842 |
| 0/0.3 | 0.917 | 0.8125 |
| 0/0.4 | 0.911 | 0.772 |
| 0/0.5 | 0.90 | 0.729 |
| 0.2/0.2 | 0.91 | 0.77 |
| 0.4/0.4 | 0.846 | 0.50 |
-
选一些方法(最多)在三个数据集上做实验(理想环境下) 0.5/0.7
-
再选择一些方法(选一些比较robust的)在三个数据集上做个0.2/0.2的噪声环境下实验,并比较不同噪声等级下的变化(loc/heading)
-
结果可视化, 多个数据集下与其他方法对比即可 注意力可视化?
-
在三个数据集下不同部分消融实验.在default city ,culver,V2XSet上测试即可
-
再选择几个方法三个数据集不同通信量结果比较(如何改变通信量)
目前问题 缺少在V2XSet上实验数据,包括自己的模型和其他的模型.
在Opencood上也缺少部分其他方法的结果
Communication Volume
compression ratio
Ablation Study
各个组件
一些超参数设置
一些组件中的方法
Robust to pose error
暂不考虑time delay

Communication Mechanism
具体来说,对于多代理通信机制,使用范围信息监督ego代理关注范围内更近的物体,其他代理关注范围内更远的物体,因为在近处包含的点云数量要比远处多很多,ego代理需要环境内更远的信息.在选择哪些特征进行传递时,通过调整后的ego特征构造的请求图生成通信矩阵,根据通信矩阵选择传递的特征以减少冗余特征并提供互补信息
Feature Enhance(local and agent-wise attention enhance)
提出一个局部和代理间的注意力增强模块.针对特征表达力不足的问题,结合范围感知的卷积模型,局部注意力模块对于特征图上不同位置的赋予不同的权重,对于跨代理的交互,在代理间通道和空间汇集信息,同时增加相对距离编码信息捕获距离感知的语义信息.通过这个特征增强阶段同时得到了不同层次的特征有助于后续融合
针对特征融合时不全面的问题,忽视范围信息的问题,我们使用局部和代理间模块生成不同颗粒度的特征用于灵活的调整不同代理以及不同空间的特征,同时考虑了特征在不同空间位置以及不同距离的代理的权重
Feature fusion
为了融合不同颗粒度的特征,结合不同特征对于最终输出的不同贡献,我们使用适应性层次融合模块调整局部和跨代理特征结合多样的表征以得到有效的融合结果.
contributions
我们提出了CoRange,基于范围感知的多代理协作感知框架.这个框架在通信机制和特征增强以及融合上与其他方法有独特的差异并取得了在带宽和检测性能上合理的平衡,并在大量的实验上表明了它比之前的SOTA模型的的竞争性.
related work
摘要
用点云进行3D目标检测在自动驾驶领域应用广泛,它通过输出目标物体的碰撞框进行感知。自动驾驶汽车的现代感知系统对遮挡物非常敏感,而且缺乏远距离感知能力。通过车辆协同感知能使CAV与场景中其他汽车进行数据通信(共享信息)并进行特征融合,使得被遮挡的点云通过其他CAV被车辆感知到,与单个智能体相比,大大提升自动驾驶的可靠性和安全性.
现有的自动驾驶系统大多基于单车的有限检测,受到稀疏,受遮挡点云的影响较大
协作感知的精确度主要受到两方面的影响,一个是单车localization error,另一方面是进行特征融合时的策略,有效的特征融合模型能改进特征选择和信息聚合从而提高感知可靠性。
我们提出了基于范围感知注意力特征融合模块,包括对于单车进行目标检测时的范围感知以及与场景中其他车辆进行特征融合时的注意力模块,范围感知注意力能改善对于远近物体的特征提取,而特征融合模块综合利用了单车局部信息和场景内通信车的特征。
(除噪模块)
在数据集OPV2V和V2XSet以及V2V4上进行实验,验证了性能。
介绍
使用LiDAR点云的3D目标检测目前取得了长足发展,然而受制于LiDAR点云的一些缺点:离激光雷达的点云非常稀疏,在真实世界中周围物体容易受到遮挡导致几乎没有点云生成,也因此单智能体的感知能力有限
由于深度学习的发展,神经网络能够高效处理大量数据.点云数据能提供 通常图像数据不具备的深度信息.准确的目标检测是实现自动驾驶的重要基础(The precise perception system, such as 3D object detection, forms the fundamental foundation for subsequent motion planning and control in intelligent vehicles. This underscores the significant influence it holds over the safety of driving in intelligent vehicles.),但由于距离较远的点云数据更加稀疏,导致感知到较远距离下的物体更难,此外,在现实复杂的环境下会频繁出现周围物体遮挡的情况导致检测准确度下降
利用车队车或车与infras协同感知使得ego车辆与一定通信范围的CAV共享信息,通过互相传递信息并在车上进一步处理,最后在ego车辆上输出感知结果碰撞框.根据共享数据的时间以及类型,可以将协同感知大致分为三种类型:1)早期融合:互相通信的车辆之间传递传感器的原始数据,在ego车辆上聚集信息并进行处理感知,2)中期融合:各个CAV处理自身捕获到的点云数据得到特征图并共享给ego车辆.3)后期融合:各辆CAV输出对周围环境的目标检测结果并共享给ego车辆进行最后碰撞框的调整.另外也有研究结合了不同阶段的融合从而更加充分地利用获取地传感器数据.
最近的最新研究[10]、[15]表明,中间融合是检测精度和带宽要求之间的最佳权衡。本文也关注 V2V 协同感知通信过程中的中间融合。Learning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication
随着这一领域的逐渐发展,一些模拟以及来自真实世界的数据集因此产生。
相关工作
协同三维物体检测利用多个智能体之间的通信来促进信息交流,从而提高在实际场景中的检测性能,包括涉及物体遮挡的情况。这个问题可以表述为,在给定的情景中,有M个代理${A_1, A_2, \dots, A_m}$可以自由通信,每个代理$A_i$通过自己的处理模块得到特征$R_i$,其中一个代理被指定为自我代理,其接收到的来自其他代理的数据为$R_{i,i\neq{ego}}$,自我代理使用专用处理模块$F(\downarrow{R_{i, i \neq \text{ego}}}, R_{\text{ego}})$将自身的特征与其他代理接收到的数据相结合,其中向下箭头表示传输时对于信息的可能的损失,最后通过header网络得到对应的检测框。
近年来,研究者们present了许多共同感知的数据集,包括利用CARLA模拟仿真得到的以及在真实世界采集得到的,在这些高质量数据集推动下,一系列方法被提出来解决现实中的问题,包括…
在这些高质量数据集推动下,一系列方法被提出来解决现实中的问题,其中主要是使用中期融合方式,这些算法从解决bandwidth-performance的根本问题下出发,从数据如何融合以及通信问题等角度解决.
discoNet提出discoGrap模拟自适应的协作感知,并利用teacher-student框架训练DiscoGraph.V2VNet利用GNN通过多轮信息传输进行合作感知,when2comm
研究发现,中期融合能在保证性能的基础上大大的节省原始数据传输带来的高带宽.
最近,一些方法采用图神经网络大大提高了融合性能并解决通信问题,…,此外,还有一系列以注意力机制为基础的方法,通过使用改进的注意力机制或者transformer模型有效地融合来自其他代理的信息。在通信问题上,研究调查了lossy communication,latent aware,pose error,还有研究异构以及adaptation
参考一些论文的abs和intro
Learning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication
abs
Deep learning has been widely used in intelligent vehicle driving perception systems, such as 3D object detection.
深度学习广泛应用于智能车辆驾驶感知系统,比如3D 目标检测.
One promising technique is Cooperative Perception, which leverages Vehicle-to-Vehicle (V2V) communication to share deep learning-based features among vehicles.
协作感知技术是有前景的技术,利用了车队车通信在车间之间共享基于深度学习得到的特征
However, most cooperative perception algorithms assume ideal communication and do not consider the impact of Lossy Communication (LC), which is very common in the real world, on feature sharing. In this paper, we explore the effects of LC on Cooperative Perception and propose a novel approach to mitigate these effects.
然而大多数协同感知算法假设通信是理想的,没有考虑过现实环境的有损通信对于特征共享的影响.本文探讨了有损通信对合作感知的影响,提出了LC-感知修复模块和具有车内注意力和不确定性感知的车间注意模块.
Our approach includes an LC-aware Repair Network (LCRN) and a V2V Attention Module (V2VAM) with intra-vehicle attention and uncertainty-aware inter-vehicle attention.
我们利用公共OPV2V数据集证明了方法的有效性.我们的结果表明方法改善了协同感知的准确性
We demonstrate the effectiveness of our approach on the public OPV2V dataset (a digital-twin simulated dataset) using point cloud-based 3D object detection. Our results show that our approach improves detection performance under lossy V2V communication.
特别地,我们提出的方法在ap上相比现有SOTA实现了显著的提升,证明了我们提出方法的能力,能够有效提升单车基于点云的目标检测结果同时增强与其他CAV之间的interaction,弥补了特征(互补了特征?)。
Specifically, our proposed method achieves a significant improvement in Average Precision compared to the state-of-the-art cooperative perception algorithms, which proves the capability of our approach to effectively mitigate the negative impact of LC and enhance the interaction between the ego vehicle and other vehicles. The code is available at: https://github.com/jinlong17/V2VLC.
intro
在复杂的真实世界中如何准确感知周围物体对于现代智能车的研究十分重要.准确感知系统比如3D目标检测是下一代运动规划的控制的基础,这对智能车辆的驾驶安全影响巨大.
HOW to perceive the surrounding objects precisely in complex real-world scenarios is critical for modern intelligent vehicle research. The accurate perception system (e.g., 3D object detection) is the fundamental base for the next motion planning and control of the intelligent vehicles, which implies tremendous impacts on the driving safety of intelligent vehicles
由于目前单个智能车辆的感知能力有限,CAV的协同感知引起了研究界和工业界的广泛关注,与单个智能车辆的感知相比,现有研究表明协同感知能显著提升感知性能.
Because of the perception limitation of the current individual intelligent vehicle [7]–[9], the cooperative perception of Connected Automated Vehicles (CAV) recently attracted much attention in this research community.
Compared to the perception of individual intelligent vehicles, recent studies [10]–[12] show that cooperative perception of CAV can significantly improve the perception performance by leveraging Vehicleto-Vehicle (V2V) communication technology for information sharing
在V2V之间共享信息是协同感知的重要一项技术,可用于在复杂交通环境中观察到更大范围和被遮挡的汽车、行人等。有三种在V2V中共享信息的方式:1)早期融合 共享原始传感器数据 2)中期融合 共享基于深度学习网络输出的中间特征 3) 晚期融合 共享检测结果. 最近的研究表明中期融合能表现出良好的检测准确度,同时带宽占用保持在合理范围。这篇文章主要关注V2V通信过程的中期特征融合
Information sharing through V2V communication is an important technology for CAV cooperative perception, which is utilized to observe a wider range and perceive more occluded objects in the complex traffic environment [13], [14]. There are three ways for information sharing during V2V communication:(1) sharing raw sensor data as early fusion, (2) sharing intermediate features of the deep learning based detection networks as intermediate fusion, (3) sharing detection results as late fusion. Recent state-of-the-art studies [10], [15] show that intermediate fusion is the best trade-off between detection accuracy and bandwidth requirement.
针对V2V协同感知提出了许多融合方法,然而它们都假设是理想环境. 有研究协同感知只考虑通信延迟的,
在城市交通场景中,V2V通信容易受到一系列因素而导致有损通信.迄今为止,还没有任何研究探讨了有损通信(LC)对复杂真实世界驾驶环境中 V2V 协同感知的影响。在城市交通场景中,V2V 通信很容易受到一系列因素的影响而导致有损通信,例如障碍物(如建筑物和车辆)的多路径效应[17]、快速行驶的车辆带来的多普勒频移[18]、其他通信网络产生的干扰。
有损通信导致的共享中间特征不完整或不准确会影响 V2V 协同感知的效果和效率。如果不能解决合作感知中的低电平问题,就会导致感知性能下降、碰撞风险增加和交通效率降低。
这篇文章首先研究了有损通信的负面影响,然后提出了一种新型的LC感知特征融合方法来解决这个问题.具体来说,提出的方法包括LCRN来恢复由于有损通信分享的共享的特征以及一个专门设计的V2V注意力模块,加强ego vehicle与其他车辆之间的关联.
V2VM包括ego vehicle的车内注意力,车间的不确定性感知attention.本文在基于合作感知的数据集进行验证.本文贡献总结如下:
我们首次提出了在有损通信下的V2V协同感知(基于点云的3D目标检测),主要关注检测性能.
这篇文章提出新兴的中间LC感知特征融合方法来减少有损通信下的副作用,通过LC感知修复网络并通过专门设计的V2V注意力模块平衡ego vehicle和其他vehicle的关联.
我们在公共的协同感知数据集上评价了提出的的方法.
文章剩下的组织如下,第二节简要回顾了与本研究相关的文献,第三节详细介绍了所提出的有损通信下的 V2V 协同感知方法,第四节提供了两种场景下的实验和分析:第五部分给出了最终结论。
This paper first studies the negative effect of lossy communication in the V2V cooperative perception and then proposes a novel intermediate LC-aware feature fusion method to address the issue. Specifically, the proposed method includes an LC-aware Repair Network (LCRN) to recover the incomplete shared features by lossy communication and a specially designed V2V Attention Module (V2VAM) to enhance the interaction between the ego vehicle and other vehicles. The V2VAM includes the intra-vehicle attention of ego vehicle and uncertainty-aware inter-vehicle attention. It is challenging to collect the authentic CAV perception data with lossy communication in real-world driving, and considering the advantage of the digital twin in many application [21][26], this paper evaluates the proposed method in a digital-twin CARLA simulator [16] based public cooperative perception dataset OPV2V [10]. The contributions of this paper are summarized as follows.
相关工作
对于自动驾驶的3D协同感知
3D目标检测是自动驾驶感知取得成功的最重要的方式之一,基于传感器的modality可以分为几种:1)基于摄像头的检测方法使用单张或多张 RGB 图像检测 3D 物体 [28]-[30]。例如,CaDDN[28] 利用深度分布与图像特征,生成用于三维物体检测的鸟瞰图。VoxelNet [29] 在三维空间中构建一个三维体,并对多视角特征进行采样,以获得用于三维物体检测的体素表示。DETR3D [30] 利用查询对提取的二维多摄像头特征进行索引,以直接估计三维空间中的三维边界框。
2)基于Lidar的检测方法,基于激光雷达的检测方法,这些方法通常将激光雷达点转换为体素或柱状体,从而产生基于体素[31]、[32]或柱状体的物体检测方法**[33]-[35]。PointRCNN [36] 提出了一种基于原始点云的两阶段策略,首先学习粗略估计,然后利用语义属性对其进行改进。有些方法[31]、[32]建议将空间分割成体素,并按体素生成特征。然而,三维体素的处理成本通常很高。为了解决这个问题,PointPillars[37]提出将沿 Z 轴的所有体素压缩成单个支柱,然后预测鸟瞰空间中的三维方框。此外,最近的一些方法[38]、[39]结合了基于体素和基于点的方法来联合检测三维物体。
3)相机-激光雷达融合检测方法提出了一种融合图像和激光雷达点信息的方法,这是三维物体检测的一种趋势。在多模态融合中,如何将图像特征与点云对齐是一项挑战。
为了解决这一难题,一些方法[40]-[42]采用了两步框架,即在第一阶段检测二维图像中的物体,然后利用获得的信息进一步处理点云进行三维检测。而其他作品 [43], [44] 则开发了端到端的融合管道,并利用交叉关注机制来执行特征对齐。本文的工作重点是基于合作点云的三维物体检测,以实现快速处理和实时性[33]、[34];在接下来的实验中,我们将采用基于支柱的方法。
Vehicle-to-Vehicle Cooperative Perception
三维感知方法的性能在很大程度上取决于三维点云的精度。然而,激光雷达相机存在折射、遮挡和远距离等问题,因此在一些具有挑战性的情况下,单车系统可能会变得不可靠。
The performance of a 3D perception method highly depends on the accuracy of 3D point clouds. However, LiDAR cameras suffer from refraction, occlusion, and long-range distance, so the single-vehicle system could become unreliable under some challenging situations
近年来,人们提出了车对车(V2V)/车对基础设施(V2X)合作系统,通过使用多辆车来克服单车系统的缺点。不同车辆之间的协作使三维感知网络能够融合来自不同来源的信息。
按照早中晚期介绍/根据融合方法介绍(注意力机制和图神经网络)
以前的一些方法使用早期融合技术在不同车辆之间共享原始数据。例如,Cooper [45] 融合了来自不同联网自动驾驶车辆的点云,并根据对齐的数据进行预测。AUTOCAST [46] 交换了来自不同传感器的传感器读数,以扩大单个车辆的感知范围。
其他方法则使用后期融合来整合每辆车的 3D 检测结果。Rawashdeh 等人[47] 提出了一种基于机器学习的方法,该方法共享每个被跟踪物体的维度和中心点位置。
其他一些后期融合方法 [48]、[49] 也采用了点云作为来自车辆和基础设施的传感器数据。
早期融合需要更大的带宽和数据传输速度,晚期融合非常依赖每辆车生成的结果,由于个体预测存在偏差,可能会产生不理想的结果。为了找的数据带宽和检测精确度的平衡,最近的方法在关注共享中间信息的中期融合.较早的方法使用
F-cooper [12] 应用了两辆汽车的体素特征融合和空间特征融合,V2VNet [13] 采用图神经网络来汇总从每辆车的激光雷达中提取的特征。V2X-ViT [15] 提出了一种视觉转换器架构,用于融合车辆和基础设施的特征。Cui 等人[50]提出了一种用于点云处理的基于点的transformer,可将协同感知与控制决策结合起来。s.Luo 等人[52]利用注意力模块来融合中间特征,增强特征互补性。Lei 等人[53] 提出了一种延迟补偿模块来实现中间特征级同步。Hu 等人[54]提出了一种空间置信度感知通信策略,通过关注感知关键区域来减少通信量以提高性能。OPV2V [10] 利用自我注意模块来融合接收到的中间特征。CoBEVT[11]提出了局部-全局稀疏注意力,可捕捉不同视图和代理之间复杂的空间交互,从而提高合作感知的性能。
然而,这些融合方法都是以理想通信为前提的,而在现实世界中,有损通信会导致性能急剧下降。为了解决这个问题,我们设计了一种特殊的 V2V 注意模块(V2VAM),包括自我车辆的车内注意和不确定性感知的车辆间注意,以增强 V2V 交互。
V2V感知中的通信问题
V2V和V2X通信可以通过与周围vehicle或infrastructure交换信息改善自动驾驶的安全和可靠性问题.然后车辆之间的通信可能会带来新的问题,由于在无线信道中有损通信不可避免,一些因素如信道错误、网络拥塞、延迟等都会造成数据丢失或错误.
通信延迟,通信数据错误(包丢失,错误)
低延迟和高可靠性是V2V通信面临的两大共同挑战,一些研究提出了具体资源分配方案等等.
有损通信也是V2V通信中的关键问题,发射器和接收器之间的障碍物会导致信号功率波动从而造成数据包丢失,共享数据还有可能在到达目的地之前受到其他信号干扰或攻击.从而导致数据丢失. 在这项工作中旨在提出一种LC感知网络消除有损通信,并提高感知网络的鲁棒性.
Adaptive Feature Fusion for Cooperative Perception using LiDAR Point Clouds
abs
合作感知使得网联车(CAV)与其他周围的其他CAV进行交互以增强对周围物体的感知从而提高自动驾驶的安全性和可靠性. 这可以弥补传统安东尼车感知的局限性,比如盲点、 低分辨率和天气影响. 合作感知中间融合方法的有效特征融合模型剋改进特征选择和信息聚合,进一步提高感知精度.
我们提出了具有可训练特征选择模块的自适应特征融合模块,其中我们提出的spatial-wise 自适应特征融合比其他OSTA在OPV2V上表现更好,
此外,以往研究只测试了车辆探测的合作感知,然而行人在交通事故中受重伤的可能性更大,使用了CODD数据集评估了合作感知在车辆和行人检测方面的性能,在CODD数据集上我们家狗比其他SOTA模型实现更高的AP,实验表明与传统的单一车辆感知过程相比,合作感知也提高了行人检测的准确性.
Introduction
近年来,利用激光雷达传感器进行三维物体探测在自动驾驶汽车(AV)中变得越来越重要[5, 10, 20, 28, 31],因为它可以提供更多有关感兴趣物体的空间信息,包括其位置、大小和方向。
激光雷达可以生成包含精确深度信息的点云数据,受外部光照条件的影响较小。但是,远离激光雷达的点云非常稀疏,这就增加了探测更远物体的难度。
被遮挡的物体会生成更少的点云,对于更小物体增加了检测难度.
合作感知使得网联车和路侧装置能够在通信范围内使用车载通信系统共享感知信息.感知信息可包括GPS和各种传感器数据,包括雷达和就摄像头和激光雷达数据,协同感知有助于弥补当前视觉感知技术的局限,比如有限的分辨率,天气影响和盲点等.
根据 CAV 之间共享的数据类型,现有文献中发现了三种数据融合方法:1) 早期融合[4] 聚合来自其他 CAV 的原始输入传感器数据;2) 中间融合[3, 16, 22, 27] 聚合来自其他 CAV 的经过处理的特征图;3) 晚期融合[9, 30] 聚合来自其他 CAV 的物体检测预测输出。最近的研究一再证明,**与早期和晚期融合方法相比,中间特征融合是最有效的融合方法。我们假设,通过实施有效的特征选择和融合模块,降低计算成本,可以进一步改进中间融合方法,以实现实时感知和更高的精度。**我们假设,通过实施有效的特征选择和融合模块,降低计算成本,可以进一步改进中间融合方法,以实现实时感知和更高的准确性。
V2V通信使得车辆之间能投通过有低带宽和受限的通信范围的无线网络进行通信,因此,高效的特征提取和数据传播以及数据融合对于协同感知是必不可少的.
由于Point_Pillar骨干网络结构相对简单,其将点云处理为二维的pillar并且检测精度相对较高,因此适用于点云编码,采用二维卷积CNN的特征提取模块进一步从编码点云中提取特征,由于对网络模型的准确性和效率都有考量,基于此,提出了几种带有可训练的神经网络的特征融合模型,自适应地从CAV中选择特征.
贡献:这个工作地贡献如下:1)我们使用了一个轻量的中间融合协同感知架构;2)我们将 3D CNN 和自适应特征融合用于协同感知,并提出了三种可训练的协同感知特征融合模型
3)在公开数据集上验证了提出方法的性能 还使用CODD数据集处理车和人的识别任务.
4)使用不同CAVs数量观察对协同感知的影响.
在 OPV2V Default CARLA Towns 的车辆检测任务和 OPV2V Culver City 的领域适应任务中,我们的 S-AdaFusion 模型优于所有现有模型。我们还在 CODD 数据集的车辆和行人检测任务中验证了我们的模型。我们的模型比所有其他最先进的(SOTA)模型获得了更高的平均精度(AP)。我们的实验还证明,与传统的感知过程相比,利用激光雷达点云进行合作感知可以提高行人检测的准确性。
这篇文章组织如下.第 2 节介绍了合作感知和特征融合模型方面的相关工作。第 3 节和第 4 节分别介绍了我们提出的合作感知框架和特征融合模型。第 5 节介绍了实验结果。第 6 节是本文的结论部分,并列举了未来的工作。
Background and related work
我们首先介绍了合作感知的形式描述和相关的特征集成方法作为背景概念。然后,我们讨论了相关工作,以突出与我们的研究贡献相关的研究空白。
Cooperative Perception
合作感知问题的形式可描述如下。我们将原始输入数据(摄像头数据和激光雷达数据)记为 I = {I1, I2, ., In} ,来自周围一组 CAV 的数据为 V = {v1, v2, ., vn}。针对输入数据提取的相应中间特征集表示为 F = {F1, F2, ., Fn},其中物体检测器的预测输出集表示为 O = {O1, O2, ., On}。 在传统单车视觉感知过程中,一辆自动驾驶车辆vi其他传感器接受从原始数据Ii然后对这些数据进行处理,提取特征图Fi,用于计算模型预测物体输出Oi. 在协同感知中,额外的数据融合步骤用于汇聚来自其他车辆的数据用于提升感知精度.
研究者提出(demonstrated)三种数据融合方法(早期,中期,晚期)根据在数据时数据的类型.
CAVs在早期绕那个和传播原始传感器数据I会造成最高的数据传输成本. 后期融合共享并汇总来自其他CAV的预测结果O,这减轻了传输负担,但是目标检测的表现高度依赖其他CAV的预测结果以及对于预测的后处理.
通过优化单车三维物体检测器和后处理方法,可以提高早期和晚期融合的协同感知性能
中间融合时提升处理中间特征表示的折衷方案,因此**,准确、优化地整合和处理从不同位置获取的信息,对于有效地进行特征融合以实现准确的目标检测至关重要**。
Marvasti 等人将3DLidar点云warp成鸟瞰图并在每个自动驾驶车中使用2D CNN来提取中间特征,来自其他CAV的特征图投影到ego vehicle的坐标系统中.然后这些信息与ego vehicle的特征图进行汇集,在 [16] 中,只使用了两个 CAV,并且求和使得重叠部分的权重较大,而在实际场景中,CAV 的数量各不相同。我们计算的是重叠处的平均值。Chen 等人[3]提出了特征级融合方案,并选择重叠处的最大值来代表中间特征。其结果是.
上面提到的是利用简短运算比如求和和最大、平均等计算,这些运算可以处理重叠部分信息,并且计算成本较小,然而由于缺乏信息选择和数据这些选择的特征并不一定是必要的(最好的).
在V2VNet中,GNN来表示基于地理坐标的 CAV 地图,以促进数据融合。GNN能从多辆车辆接受信息并于车的内部状态计算一个新的中间表示.Xu 等人[27]提出了 AttFuse,并利用自我注意模型[21]来融合中间特征图。V2X-Vit[26]和 CoBEVT[25]利用transformers进行中间特征融合的合作感知。
我们三所的特征融合可以搞笑利用来自CAV的特征图.
Feature Learning and Feature Fusion
注意力机制已在解决计算机视觉任务中证明了其实用性[8, 18, 21, 23]。通过在神经网络中加入一个小模块,该模型可以利用通道和/或空间信息,增强提取的表征。
在过去的三维物体检测中,人们也探索过摄像头和激光雷达的特征学习和特征融合。Yoo 等人[29]提出了一种自适应门控融合网络,用于结合激光雷达和图像特征。
Liu 等人[15]和 Liang 等人[11]提出了一种 BEV 融合方法,该方法将相机拍摄的图像和激光雷达生成的点云的中间特征投射到 BEV 中,并沿通道轴串联两个特征图。Liu 等人[15]利用卷积编码器生成基于 BEV 特征图的精细融合图。Liang 等人[11]提出了一种动态融合模块,并应用信道关注来自适应性地选择特征。
在协同感知中,通过特征信道将中间特征图串联起来,会随着 CAV 数量的增加而大大增加计算成本。因此,与其合并特征图并创建一个额外的大型特征提取网络,不如将带有几何和地理信息的特征图汇总在一起,这样会更有效。
CORE: Cooperative Reconstruction for Multi-Agent Perception
abs
这篇文章提出了CORE,一个概念简单,高效且通信效率的多agent协同感知模型,它从合作重构的新角度解决了问题,基于以下两个关键想法:合作代理共同提供对环境更全面的观察 2) 整体观察作为一种有价值的监督,明确指导模型学习在合作基础上如何重建理想的观察
CORE通过三个主要组件实现这个想法,为每个agent创建一个compressor,以创建更紧凑的特征表示,从而实现高效广播. 一个用于跨agent信息聚合的轻量级贴心协作组件,重构模块,根据汇总的特征表征重构观测结果.
这种学习-重构的理念与任务无关,可以提供清晰合理的监督,激发更有效的写作,最终促进感知任务的完成.
我们在公开数据集OPV2V,一个大型的多智能体感知数据集上验证了CORE,并使用了两种任务,3D目标检测和语义分割.
结果表明达到了最先进的性能并且有更高的通信效率.
intro
感知-识别并解释sensory感官信息对于智能车感知周围环境是关键的能力,由于深度学习的不断进步,个体感知在许多任务中都取得了显著成就,比如检测,分割和跟踪.
即使有广大前景,由于单个智能体受限的视线能见度,它也存在很多问题.,并面临安全问题的挑战.
更有说服力的范式是协作感知. 即一组智能体表现得像一个团体通过互相交换信息以此使用它们结合的感知经验来感知.沿着这一方向,最近已在努力提供数据集和合作解决方案
这些解决方案都认为多个智能体共同提供对环境的整体观察.但是这里存在一个性能和带宽平衡问题需要解决,因此,一些研究使用了自适应通信架构来为每个agent减少带宽,其他研究关注了多智能体协作策略. 比如早期协作汇聚原始对于协作只能提的原始观察.晚期融合直接每辆车预测得到的结果。
流行的中间写作融合易于压缩中间特征表示. 即使这些方法在许多领域都有应用,从自动驾驶到搜索和救援,一个关键问题没有得到解答.
信息交换和汇总后,每个agent的理想感官状态应该是怎样的?信息交换和汇总后,每个agent的理想感官状态应该是怎样的?
我们的主要见解是,如果多个代理一起确实能对场景进行更完整的观察,那么通过吸收其他代理的信息,代理就能重建其部分原始观察中缺失的部分。
本文从合作重建的角度提出了新的方法,主要观点是如果多个agent通过接受agent的信息,共同对场景进行更完整的观察,那么一个agent就能重建其部分原始观察中缺失的部分.
通过学习重构,模型能学习到高效的与任务无关的特征表示,此外,这种学习-重构的思想与最近在掩码数据建模上的发展有自然关联,使我们的模型能够从获得的更多损坏输入中恢复完整的观察结果.
有这种能力后就能允许智能体交换空间的系数特征减少传输开销.
给定一组智能体和其鸟瞰图,CORE通过三个关键模块
论文修改
- 在实时应用中训练和部署 CoRange 框架的具体计算要求是什么?
- 作者能否提供有关超参数调整过程的更多细节,以及 CoRange 中不同模型和组件所使用的具体数值?
- 加文献
- 虽然总体语言专业,术语使用准确,但有些部分过于冗长。建议简化语言,避免重复描述。尤其是非关键性的细节,可考虑减少或移至附录。
- 尽管方法部分已经相当详细,但一些技术细节可能仍不清楚。例如,在介绍特征提取、通信机制和融合模块时,提供伪代码来说明关键步骤可能会有所帮助。
- 论文中的所有技术假设是否合理?例如,假设所有合作车辆都能准确共享位置信息,所有传感器数据都可靠且无噪音。如果这些假设过于理想化,可能会影响该方法的实际应用。此外,还要评估模型的计算复杂度,特别是在处理大规模数据集和多车辆协作场景时的效率。如果计算复杂度过高,可能会导致实时性较差,从而影响实际应用。
- 论文中的创新是仅仅停留在表面上(如简单的算法组合或参数调整),还是真正深入问题的本质,提出全新的解决方案或方法?
- 在引言中,关于通信和计算资源消耗以及现有方法抗噪声能力差的论述过于曲折,使人难以清晰地把握作者的研究动机。
- 在图 3 中,CMG 模块的输入包括 Ego 代理和代理 j。然而,在子图(a)中,CMG 模块的输入只显示了代理 j,这就造成了歧义。此外,在子图(b)中,fgen(-) 操作的图示并不完整,缺少了论文中描述的检测头和最大值操作,因此很难理解这些组件在哪里发挥作用。
- 在第 5 页,作者声称:“我们假定,随着与自我代理的距离增加,感知权重也会增加,从而推断出离自我代理较远的位置具有更大的重要性”。然而,实验部分并没有提供任何视觉结果来支持这一论断。
- 所提出的范围感知通信机制可以自适应地生成范围感知通信图,从而减少冗余数据,使自我代理能够专注于探测远处或被遮挡的目标。不过,实验部分没有提供任何直观结果来证明其特征选择能力。
可视化一节添加attention weight map可视化权重,特征选择矩阵
模型介绍和训练细节部分增加对参数调整和模型具体参数说明
推理速度以及训练、测试的计算要求(复杂度?) cobevt 参数量+FPS
在介绍和相关工作中加文献
flops and params
| model | flops/macs(G) | params(MB) | fps |
|---|---|---|---|
| fcooper | 138.01 | 7.271 | 79.66 |
| where2comm | 134.0 | 8.057 | 56.84 |
| cobevt | 222 | 11 | 20 |
| attentive | 49.376 | 6.584 | 117.84 |
| v2x-vit | 271.421 | 14.172 | 11.73 |
| v2vnet | 348.273 | 15.205 | 25.38 |
| corange(Ours) | 179.497 | 20.657 | 36.21 |
论文debate
审稿意见回复 - SXQ-BLOG - 博客园 (cnblogs.com)
gmd-2018-220-AR2.pdf (copernicus.org)
A template for responding to peer reviewer comments (editage.com)