
论文Idea(二)
论文Idea(二)
最近看到这个视频大模型时代下做科研的四个思路【论文精读·52】_哔哩哔哩_bilibili,深有感触. 作为没啥资源的人谁会去与训练大模型啊?(这里指的大模型是相对来说训练耗时间和资源的). 还是finetune吧.
现在LLM以及生成式、多模态的模型非常受欢迎,其他任务目前也常常会往这些方向上靠. 之前做了协同感知相关工作,主要侧重通信量的减少和特征融合. 现在想往弥补domain gap上靠.再次之前先回顾一下这个方向上过去的工作.
协同感知(Collaborative Perception)近期工作汇总梳理(2022上) - 知乎 (zhihu.com)
协同感知(Collaborative Perception)近期工作汇总梳理(2022下~202304) - 知乎 (zhihu.com)
以及综述http://arxiv.org/abs/2301.06262和http://arxiv.org/abs/2208.10371
关于协作感知的较早一篇工作,出自在这个领域上有很多贡献的Runsheng Xuhttp://arxiv.org/abs/2210.08451,
- 现有的多智能体感知算法通常在智能体之间共享从原始感知数据中提取的深度神经特征,以在准确性和通信带宽限制之间取得平衡。
- 这些方法假设所有智能体具有相同的神经网络,但现实中这可能并不实际。
- 当模型不同时,传输的特征可能存在较大的域间差异,这可能导致多智能体感知性能显著下降。
具体方法
- 提出了名为MPDA(Multi-agent Perception Domain Adaption)的框架,包含可学习的Feature Resizer和稀疏跨域变换器(Sparse Cross-domain Transformer)
- Feature Resizer用于在多个维度上对齐特征。
- 稀疏跨域变换器用于域适应,通过局部和全局的特征关联来生成域不变表示。
- 该框架不需要其他模型的关键信息(例如模型类型、参数),因此可以保持隐私。
截止2024年有两篇关于弥补domain gap的协作感知文章,AAAI的DI-V2X,主要是cav与inf的domain差异.目前的研究通常对来自每个代理的信息一视同仁,忽略了每个代理使用不同激光雷达传感器所造成的固有领域差距,从而导致性能不尽如人意。
还有一篇WACV的调整模型通过单一代理到协作,感觉想法很好,但是可能不会那么work.
我目前主要关注3D点云的输入数据,任务是目标检测,从数据上的domain可能只有从仿真数据到真实数据了.
从模型/代理上的domain,如果类似DI-V2X在数据上就要使用V2X,感觉就要麻烦一点.不过还行.还可以类似MPDA**,对于同一公司,由于车载软件版本的不同,也可能存在不同的检测模型.当共享特征来自不同的骨干时,存在一个明显的domain gap**.都能讲故事.
2210.15176 (arxiv.org)做了去雾的目标检测,使用了多个loss和domain classifier,其实也可以考虑用GAN?
原本的方法通过类似transfer learning,knowledge distillation的想法设计多个损失优化网络,

MCC MCD MSDA DIRT-T
这个领域的domain adaptation一般有分成虚拟和现实数据的domain以及deployment domain gap,意思是现实世界有位置噪声.
uncertainty-aware module处理除了ego代理的其他代理传来的特征,这算一种融合方式?
涉及数据集V2XViT和V2V4Real.
主要是代理异质性,和仿真和真实场景感知的domain gap.
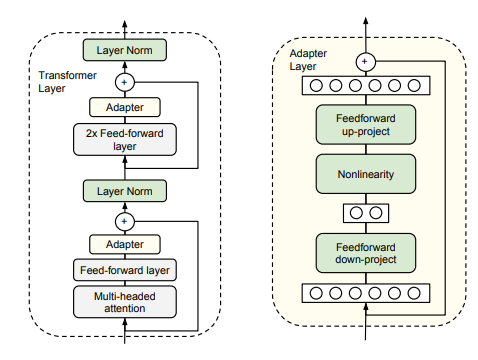
方法:adapter lora uda
domain adaptation
可能的改进方法:
1. 多尺度,不同尺度的特征上计算loss loss增加category-level?
2. soft label??
3. combined with other adversarial learning or GAN?? 数年之前的da方法汇总?? 结合object detection e.g. Domain Adaptive Faster R-CNN for Object Detection in the Wild
如果只是da,主要是loss和模型设计,这没啥太大意义,如果能跟协作感知具体融合就更好了.
在模型上
1. 使用transformer e.g.cdtrans
v2x和位置噪声、延迟的情况
可能改进的方法:
1. 基于transformer继续改进 uncertainty-aware?
2. 看看最新论文?cdtrans:Xu: Cdtrans: Cross-domain transformer for unsupervised… - Google 学术搜索
测试数据集
V2V4Real
V2Xset
dairv2x??
目的1.在仿真数据(opencood)上训练,在真实环境上也能表现好
2.在噪声、时延和异构智能体的情况下表现也好.
build a unified pipeline?
期刊
IEEE Transactions on Intelligent Transportation Systems
IEEE Transactions on Intelligent Vehicles
IEEE Robotics and Automation Letters
IEEE Access
会议
ACM International Conference on Multimedia 10月28
IEEE International Conference on Robotics and Automation (ICRA) 5月
ICCV ECCV 10月
WACV 1月
IEEE Conference on Intelligent Transportation Systems (ITSC 2024)
9月 24 - 9月27
ICRA 7月15
动机:
用以训练模型的真实数据难以获得而且标注耗时,所以通常使用模拟仿真数据训练和验证.然而由于模拟数据和真实数据之间存在巨大的域差距,现有的一些方法把这些经过模拟数据训练的模型部署到真实世界时,感知性能就会下降.
此外,真实环境下也存在相对位置的噪声、延迟以及异构智能体之间差异等问题也会造成检测能力降低的问题.
一些论文会将上面问题分成Feature gap和deployment gap的问题然后通过不同模块进行解决.
相关论文:
解决的问题:
模拟数据与真实世界数据之间存在巨大的域差距,包括传感器类型、反射模式和道路环境的差异,这往往导致在模拟数据上训练的模型在真实世界数据上进行评估时表现不佳.
此外,真实世界的协作智能体之间仍存在领域差距,例如,自动驾驶车辆和路边基础设施上可能安装了不同类型的传感器,且具有不同的外在特征,这进一步增加了泛化的难度。
解决方法:
为了实现模拟与现实的适配,设计了一个位置自适应模拟与现实适配器(LSA)模块,以自适应地聚合来自特征图关键位置的特征,并通过聚合的全局特征上的模拟/现实判别器来调整模拟数据与现实数据之间的特征。
在智能体间适应方面,设计了置信度感知适配器(CIA)模块,以便在智能体置信图的指导下调整来自异构代理的细粒度特征。
解决的问题:
与理想的模拟环境不同,在现实世界中,由于 GPS 不可避免的误差和代理与代理之间的通信延迟(时间延迟),多个代理可能会出现定位(位置和航向)误差。
此外,现实世界中的点云特征分布可能与模拟数据有很大差异,例如更复杂的驾驶场景、不同的激光雷达通道数、混合交通流、各种点云变化等。
解决方法:
同样也是分别针对两个问题提出不同模块,S2R-UViT缓解部署差距带来的不确定性。具体来说,S2R-UViT 包括一个本地和全局多头自注意力(LG-MSA)模块,用于增强所有代理的空间位置之间的特征交互,以容忍不确定性的缺点;
还包括一个不确定性感知模块(UAM),用于通过考虑不同位置不确定性水平的其他智能体共享特征来增强自我智能体特征。
解决的问题:
现有的多代理感知算法通常假设所有代理都拥有相同的神经网络模块,这在现实世界中可能并不现实。当模型不同时,传输的特征可能会有很大的域差距,导致多代理感知性能急剧下降
解决方法:
通过插入所谓的调整器模块以及通过一个判别器判断特征来自哪种类型的代理来弥补异构代理之间的差异.
我尝试解决的问题和方法
上面提到的两个问题可以概括一下,一个是在线下训练模型时,由于使用仿真数据,那么直接在现实场景中可能存在所谓域差异导致感知性能降低(数据/特征差异).
另一个是当线下训练后部署在智能体上时,由于真实环境带来的位置噪声、延迟以及异构智能体之间的域差异等问题(可以将几个问题统称为某类问题,一些论文称之为deployment gap,但考虑到这些差异其实都是由于多智能体间在协作互相传数据时可能出现的问题,可以称之为协作差距).
基于这两个问题,可以跟另一个问题融合一下.由于驾驶环境会不断改变,由固定数据线下训练的模型无法及时更新,也会导致感知性能下降.如果想要更新模型以匹配更新的驾驶场景,需要对模型再次训练以弥补这些差异.如果重新训练那成本很大,就要基于新的数据
解决办法可以考虑使用类似域适应(domain adaptation),设计模块和损失函数使得在仿真数据(LiDAR以及对应标注和真实场景数据但没有标注)下训练得到的模型在真实场景下效果依然好.
New ideas
- Transmission Efficiency in Collaborative Perception
- Collaborative Perception in Complex Scenes
- Federated Learning-based Collaborative Perception
- Collaborative Perception with Low Labeling Dependence
协作感知的一些基本问题包括,
- 减少通信时传输的数据量,因为协作与当个智能体检测的差别就是需要用到处于不同位置带来的更多视角的数据,能否在使用尽可能少的数据下依然保持良好检测能力
- 在位置噪声等存在的较为复杂环境下依然有良好的检测性能. 也就是相比单个代理更好的感知能力以及在复杂环境下的鲁棒性
- 异构代理或者异构的模型/算法带来的差异
附带的一些新趋势问题包括:
- 域适应/无监督学习. 车联网( Vehicle-to-Everything,V2X )协同感知对于自动驾驶的推进至关重要。然而,实现高精度的V2X感知需要大量有标注的真实世界数据,而这些数据往往是昂贵和难以获得的。由于模拟数据可以以极低的成本大规模生产,因此受到了广泛的关注。然而,模拟数据和真实世界数据之间显著的域差距,包括传感器类型、反射模式和道路环境的差异,往往导致在模拟数据上训练的模型在真实世界数据上评估时性能较差。此外,现实世界中的协作智能体之间仍然存在域间鸿沟,例如在自动驾驶车辆和道路上可能安装不同类型的传感器
- 减少通信量 reduce communication volume using variant vqvae or filter multi-/group-query
- 鲁棒性(位置噪声) variant transformer with deformable conv
- 迁移学习(本质同1) learn unified representation using transformer or thoughts from cycleGAN?
迁移domain_adaptation 流程 重点
减少通信量与鲁棒性(增加检测精度)
Unsupervised Domain Adaptation
V2V4Real中提出了sim2real的问题,source domain是仿真数据,target domain是真实数据,这第一眼一看就是一个迁移学习、域不变等等问题,关键是这里使用来自分别来自这两方的数据,并且还shuffle,这就相当于随便拿不同场景中的数据通过同一个模块得到不同的特征source_features和target_features,再通过相同的一个da_module计算loss,训练得到的模型再直接在v2v4测试集上测.
opt = train_parser()
hypes = yaml_utils.load_yaml(opt.hypes_yaml, opt)
print('Dataset Building')
#######################################################
# DA_Component: dataloader for source and target domain
#######################################################
source_opencood_train_dataset = build_dataset(hypes,
visualize=False,
train=True,
isSim=True)
# Modify the root to the target domain
hypes['root_dir'] = hypes['root_dir_target']
target_opencood_train_dataset = build_dataset(hypes,
visualize=False,
train=True,
isSim=False)
source_train_loader = DataLoader(source_opencood_train_dataset,
batch_size=hypes['train_params'][
'batch_size'],
num_workers=8,
collate_fn=source_opencood_train_dataset.collate_batch_train,
shuffle=True,
pin_memory=False,
drop_last=True)
target_train_loader = DataLoader(target_opencood_train_dataset,
batch_size=hypes['train_params'][
'batch_size'],
num_workers=8,
collate_fn=source_opencood_train_dataset.collate_batch_train,
shuffle=True,
pin_memory=False,
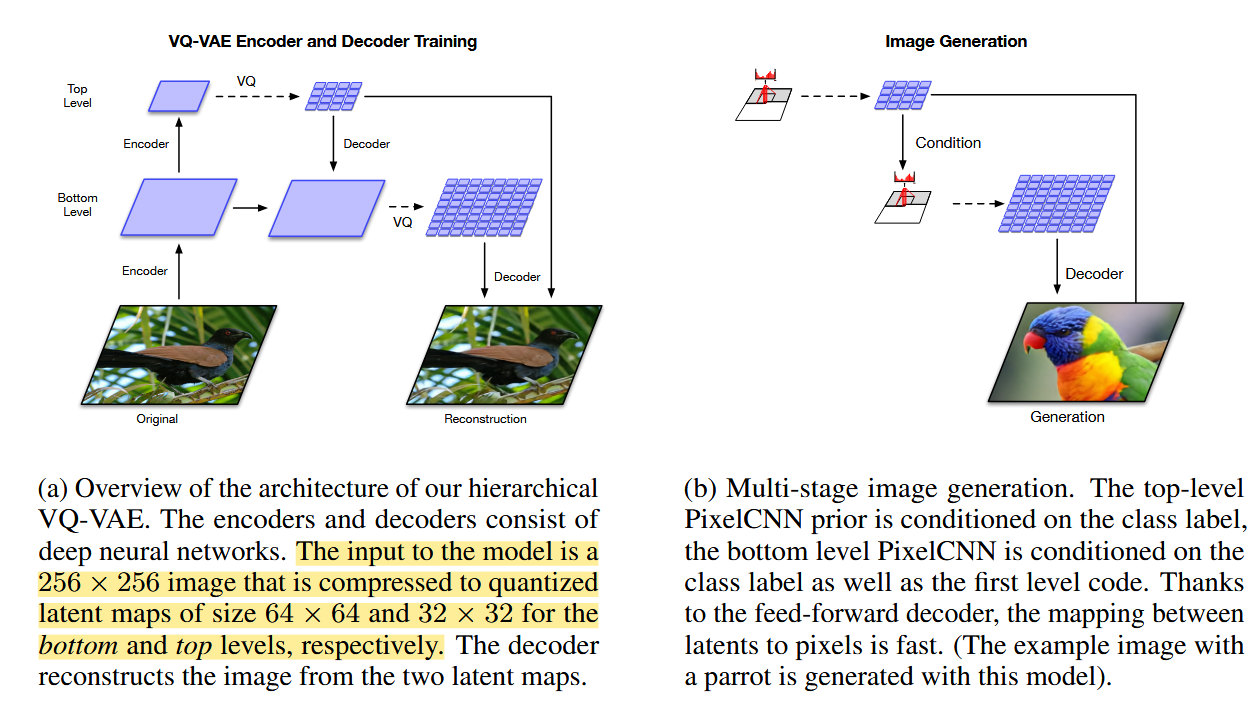
drop_last=True)vqvae+mutal information for compression and reconstruciton(ermvp filling-code)
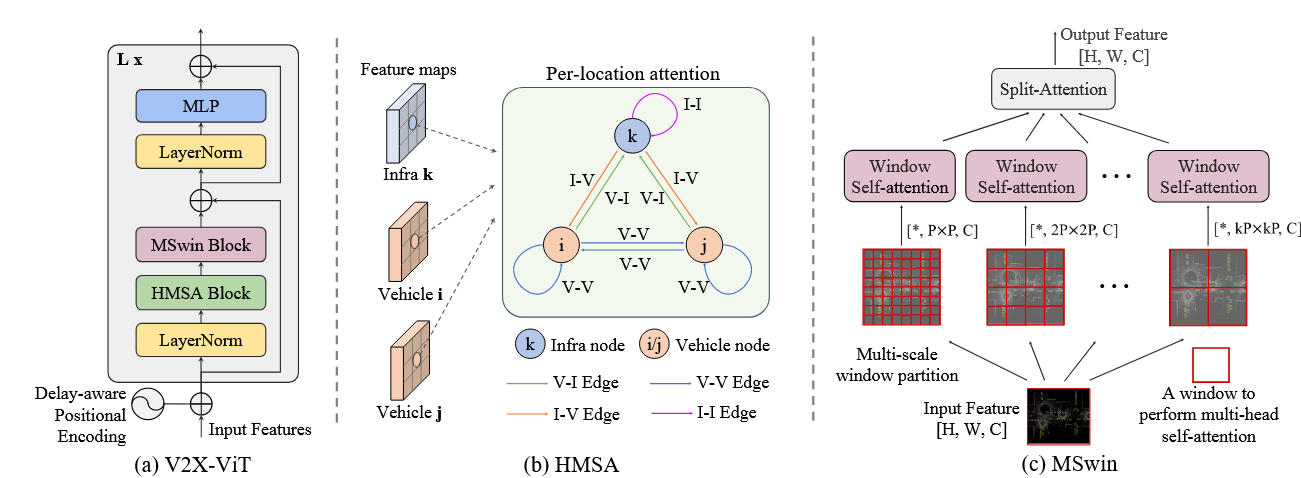
transformer multi-scale multi-window(v2x-vit v1 v2)
how2comm scope what2comm

multihead multi-scale codes
intro
近年来,多智能体协同感知在自动驾驶领域展示了一种很有前途的解决方案,以克服环境限制,如遮挡、极端天气状况和感知范围。这种感知模式允许网联自动驾驶车辆( connected and autonomous vehicles,CAVs )通过车联网( vehicleto-everything,V2X )通信与其他人共享信息,显著提高了每个CAV的感知性能。
communication
当前的方法旨在在协作所需的通信性能和带宽消耗之间取得平衡。例如,Liu等人[ 2 ]采用多步握手通信过程来确定哪些智能体应该共享信息。Liu等人[ 3 ]开发了一个通信框架,以找到与其他Agent交互的合适时间。尽管上述关于多智能体协同感知的工作已经探索了性能和带宽之间的权衡[ 4 ],以及通信图的构建[ 2 ],但这些方法都依赖于基本的邻近驱动设计,未能考虑动态网络容量对感知性能的影响。不幸的是,车载环境下的无线信道是高度动态和时变的,受到车辆间距离、车辆数量、天气状况等因素的影响。
在不考虑信道变化的情况下,现有工作无法保证传输速率和时延,这可能会导致严重的感知性能下降。为了填补这一空白,我们提出了一种信道感知策略来构建通信图,同时最小化各种信道变化下的传输延迟 (使得通信量能够动态变化)
使用vq(codebook)-based方法局限
- 由于传输的中间数据是索引,原本H*W*C的特征图变为了L*C,丢失了2维特征图的结构性 (丢失特征结构性) 将重建后的特征转为二维图后设计损失减小差异 使用multi-resolution or hierarchical vavae
- 传输索引使得高维特征变成了一维的索引,缺乏适应的通信量变化 (缺失调整通信量的方式) 选择不同数量的通道进行压缩/量化 channel-aware EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network SENet ECANet
residual quantizers?
- 重建损失 mse+mi loss
解决方法
- 使用simvq等技巧
- 结合vqvae-2 多尺度提升鲁棒性
- 设计mutual information损失
- 设计通道感知,增加通信量的适应性
使用domain adaptation方法局限
domain adaptation方法粗略分为对抗性学习和设计判断指标
判断指标不方便选定,往往需要大量实验
CDTrasn与TVT
打算通过transformer,通过window,agent,等不同尺度上的融合以及指标设计融合以及domain adaptation方法
设计不同的GRL,比如WGRL和AdvGRL
WGRL $G_{rev}=-\lambda(d\cdot p+(1-d)(1-p))G$
$\lambda$是WGRL的超参数,d是图像的域label,p是域判别器输出
AdvGRL $\lambda_{adv}=\begin{cases}\min(\frac{\lambda_0}{L_c},\beta),&\quad L_c<\alpha\\\lambda_0,&\quad\text{otherwise,}&\end{cases}$
Lc为领域分类器的损失,α为判断训练样本是否具有挑战性的硬度阈值,β为溢出阈值,避免在反向传播中产生过大的梯度,
对于spatial和global特征设计两个判别器得到相应损失CrossEntropy
B:
分为Transfer和Discrim保留不同源的一些普遍特征? 使用psm
同时使用GRL和类似Cdtrans的方法? 同时使用GRL搭配判别器和来自不同源的特征输出某个网络后的值交叉熵作为损失
同时在patch-level,global-level等不同尺度对齐特征
L:
使用convnext等替代vit中部分结构?
使用GRL变体
-13
完成 介绍和相关工作部分
-15
总结通信和域适应部分重要设计和模块